SUPERVOICE is a text-Independent speaker verification system which ultilizes ultrasound in human speech. It can be integrated with any Deep Neural Network based speaker identification model. SUPERVOICE is highly accurate in the speaker recognition task, outperforming all existing speaker verification models. SUPERVOICE is also capable of differentiating between the speech from genuine human and replay audios from attackers. With SUPERVOICE, we are exploring a new direction of human voice research by scrutinizing the unique characteristics of human speech at the ultrasound frequency band. When considering human speech production, our research indicates that the high-frequency ultrasound components (e.g. speech fricatives) from 20 to 48 kHz can significantly enhance the security and accuracy of speaker verification. SUPERVOICE could significantly enhance the existing speaker verification systems. This website shows the dataset we used to evaluate SUPERVOICE.
Team
SuperVoice was discovered by the following team of academic researchers:
- Hanqing Guo at SEIT Lab, Michigan State University
- Qiben Yan at SEIT Lab, Michigan State University
- Nick Ivanov at SEIT Lab, Michigan State University
- Ying Zhu at Michigan State University
- Li Xiao at Michigan State University
- Eric J. Hunter at Communicative Sciences & Disorders, Michigan State University
7700
Audio Samples
641
minutes of audio
305
of sentences
-
Download
-
Why we collect this dataset?
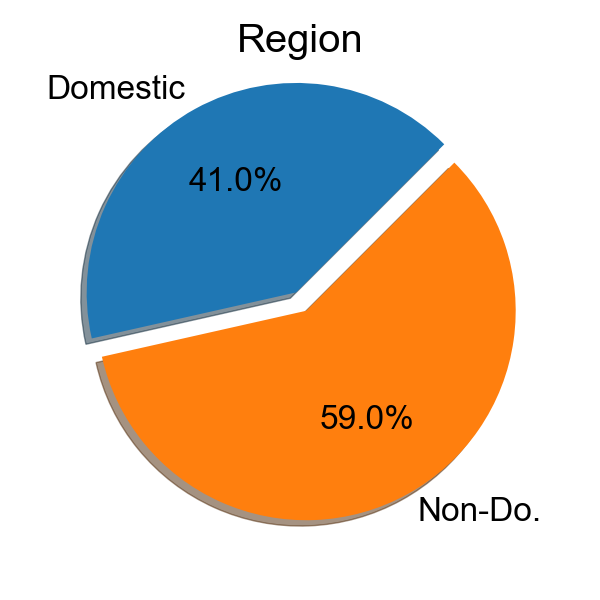
SUPERVOICE dataset (Voice-1 and Voice-2) is the first voice dataset with voice data collected by recorders with a high-frequency sampling rate as highly as 48kHz and 192kHz.
What is inside the dataset?
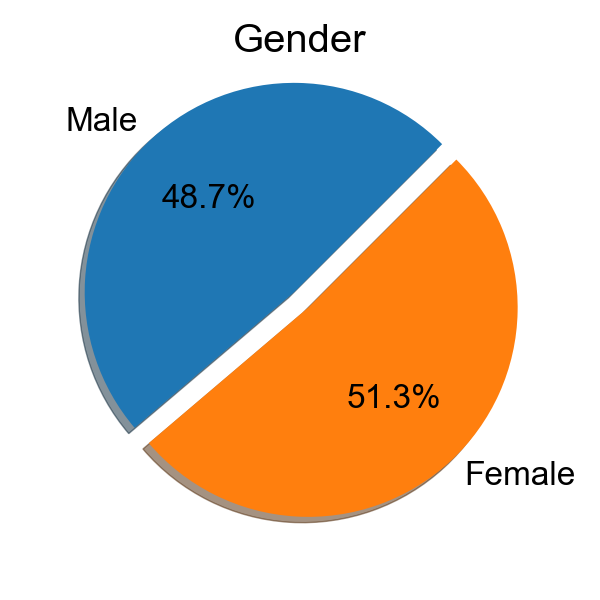
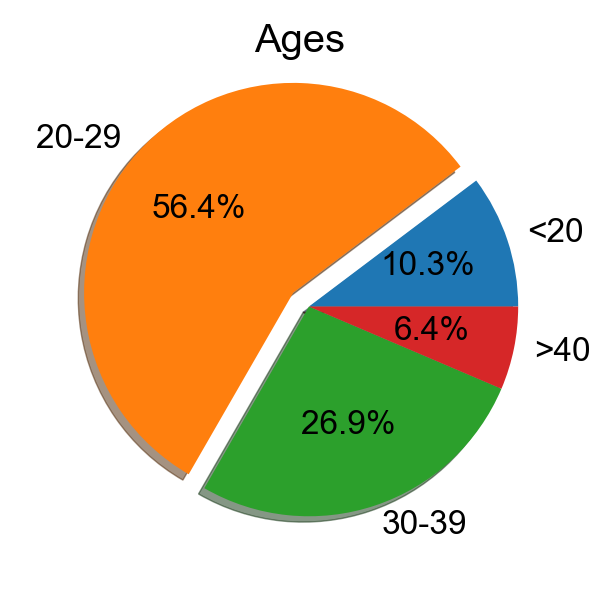
Voice-1 is collected by Avisoft condenser microphone CM16, which includes the voice data from 78 volunteers, totalling 7,800 utterances using 192 kHz sampling rate. Among the 78 volunteers, most of them are college students with ages ranging from 18 to 56, including 38 males and 40 females. Voice-2 is constructed by recording 25 sentences by 50 participants with different models of smartphones, which includes 1,250 utterances with 48 kHz sampling rate.
The table below shows a comparison with other high-profile datasets.
Dataset Size
77 person, 7700 audio samples, 100 audios/person
Dataset Design
There are 4 types of sentences included by the dataset.
- ★Common:The common type contains 5 sentences, two of which are from the dialect set of TIMIT dataset, while the other three sentences are “This is a test", “Please identify me", and “OK, please recognize my voice". For this type of sentence, each participant will speak every sentence twice, resulting in 10 recordings.
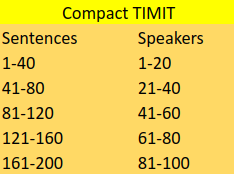
- ★Compact:The compact type has 200 sentences in total. They are randomly chosen from the TIMIT dataset, and designed to provide a good coverage of phonemes, with extra occurrences of phonetic contexts that are considered either difficult or of particular interest. Each participant reads 40 sentences from this type.
- ★Fricative:The fricative commands are collected from the website ok-google.io, which provides commonly used commands on Google Assistant. We select 50 sentences that have fricative phonemes, e.g., “find my phone", “turn on my lights". Each speaker randomly picks 25 sentences from this type of commands.
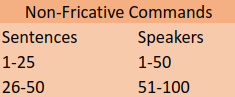
- ★Non-fricative:Similar to the fricative commands, the non-fricative commands are also collected from ok-google.io, which do not contain any fricative phonemes. We randomly pick 25 sentences and ask every participant read 25 sentences from this type
Sentences
Arrangement
We assign different speakers with different sentences, to assure every sentences are read by different speaker.

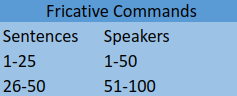
Samples
Transcript: She had your dark suit in greasy wash water all year.
Transcript: Please identify me.
Transcript: Don't ask me to carry an oily rage like that.